イベント駆動を軸とした外部システム連携
SHARES
外部システム連携と向き合って、5年ほどが経った。
最近あらためて連携まわりの開発を行ったため、2026年時点で何を考え、どのようなアプローチで実現したのかを記録しておく。仕事に関わる内容なので、抽象度の高い話にとどめる。
要件
大枠として、以下のような要件があった。
- ニアリアルタイムでトランザクションデータを捌きたい。
- 事業目線では、トランザクション連携が商売の生命線である。
- 生命線であるがゆえに、可用性と回復性を高いレベルで実現したい。
- 主体処理と付帯処理が存在し、それぞれをうまく整理して処理したい。
- データの結果整合性を許容し、非同期処理をフルで活用する。
- 複数の連携起点が存在するが、最終的な連携経路は1つに集約する。
- 登録 / 更新 / 削除 のデータライフサイクルを実現する。
なお、これ以外にも挙げきれない細かな要件が山ほど存在する。
システム分類で言えば、堅牢な基幹システム系。
要件漏れが許されないため、ウォーターフォール型の手法で開発した。
現行で運用に乗ったシステムが存在するため、先行システムの仕様を可能な限り踏襲する。
一定の開発手法の柔軟性は取れるように交渉し、調整可能な形で開発を進めた。
システム特性
要件から、特に重要で獲得を求められた特性を5つ挙げる。
- 可用性
- 回復性
- 整合性
- ニアリアルタイム性
- 独立性
これらは妥協なく獲得を目指す。トレードオフが発生する場合は相談の上で調整する。
逆に、ここで挙げない特性は妥協してもよいと判断した。
システムデザイン
システムデザインは、最終的に以下で着地した。
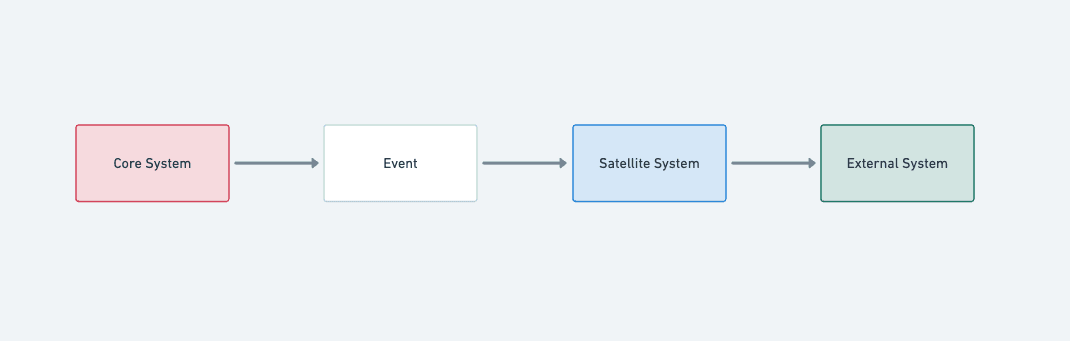
最初からこの形を描けていたわけではない。
検討当時の既存構成を尊重しつつ、新たに構成を組み上げるなら大枠はこの方向性ではないか、というイメージはあった。そこからスタートし、現在の構成に着地した。
振り返ると、初期構想から大きくは外れなかった。
一方で、外部結合テストやシナリオテストまで進んだ段階で問題が顕在化し、構成を最適化した箇所もある。
それらは設計初期には強い課題として認識できておらず、テスト過程でトラフィック量を意図的に増やして動作検証したことで、構成上の欠陥に気づいて軌道修正した。
設計変更は取引先とハレーションを生むポイントでもあったが、期待値調整と説明、交渉を重ね、無事にあるべき形へ近づけることができている。
工夫
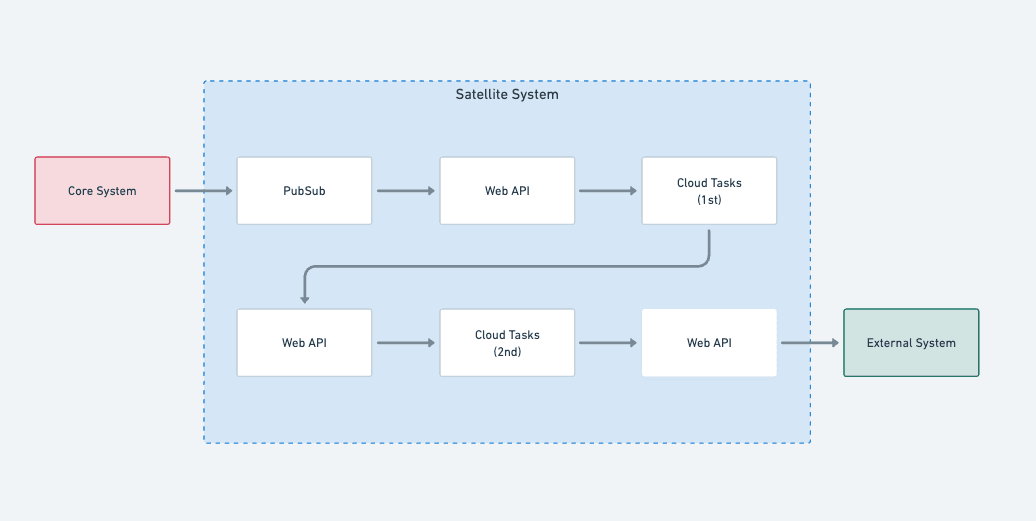
工夫1. PubSubのイベント発信基盤をフル活用する
連携対象のデータは、コアシステムから発火される「イベント」を起点に認識し、イベント発火をトリガーとして連携フローに乗せる構成を選択した。
これは、トランザクションデータが持つ性質と要求事項、そして目指すシステム構成を踏まえると、PubSubをトリガーとして採用するのが最適だと判断したため。
PubSubのイベント発信基盤では無作為にイベントが飛ぶが、連携を担うサテライトシステム側がすべて受信した上で、連携対象を取捨選択する。
コアシステム側は、イベントデータの使い手が何であろうと関知せず、とにかく自システムで起きた事実だけを送ることに専念する。
「専念する」と表現したのは、システムには主従関係があり、コアシステムが絶対的な立場でサテライトシステムが追従する、という原則でシステム構成をしているためである。
PubSubを介することでシステム間は疎結合になっており、イベントデータのスキーマ自体も頻繁に変わるものではない。そのため、安定性への懸念を持たずに開発できた。
結果として、コアシステム側を開発する人とサテライトシステム側を開発する人の間に調整を挟まずに開発を進められる、という組織スケーラビリティのメリットも享受した。
工夫2. 経路選択と連携実行の分離
ニアリアルタイム性を毀損しない範囲で、先のシステム構成にする意思決定をした。
その上で今回は、サテライトシステム内部で “経路選択” と “連携実行” の処理を分離し、別々に処理することを選択した。
結果として、“ノイジーネイバー問題” の解決と、API連携実行側の責務分離を実現した。
サテライトシステム側はPubSubでイベントを受信するが、イベントには連携対象にすべきものとそうではないものが無差別に送られてくる。経路選択で有効イベントを選別し、連携対象のみを連携実行に進め、無効イベントを捨てる判断をする。
“経路” と表現したとおり、次点に進める処理にはA, B, Cといった経路が存在し、それぞれどの経路に進めるかの処理も行っている。いわゆるデータルーティングのイメージ。
連携実行側は渡ってきたデータを素直に信用し、連携必要の有無判断 (事前条件チェック) と連携処理を行い、成否に依らず付帯処理の実行までを担う。
整理された着地ではあるが、最初からここまで責務を整頓できていたわけではない。テストなども含めて、着地点を見出した。
工夫3. Cloud Tasksのリトライとリクリエイト機構をフル活用する
コアシステムとサテライトシステム間では、PubSubのイベント連携で連携対象の共有を行っている。イベント受信後のサテライトシステム内の処理では、Google Cloud の Cloud Tasks をフル活用して逐次的に処理を重ねる構成を選択した。
なお、Cloud Tasksが呼び出す先のAPI処理 (組織内では「ユースケース」と呼称) は、必ず冪等性を担保するように設計する。これは例外を許さず、徹底して守る。つまり “原則” だ。
冪等性担保の原則を守ることで、Cloud Tasksの標準仕様であるリトライ処理の恩恵を受けられる。何らかの障害で途中処理が止まったとしても、自然回復可能な状態になる。
可用性という観点での評価は難しいが、Cloud Tasksが保証している可用性に依存するため、1度きりのリクエスト処理での可用性と比べれば十分に高い水準に至れる。
外部連携を担う箇所でもCloud Tasksのリトライ機構がうまく働くため、自然と高回復なシステム連携が実現できる。
このあたりは、技術選択がシステム特性の獲得を容易にする事例を語る上で代表例になる。技術選択 (= 意思決定) がなぜ重要なのかを人に説くときの例え話に使いたい。
工夫4. 冪等性担保と差分チェック機構による最小限のリクエスト送信
サテライトシステムが外部システムとの連携の対面に立つにあたり、外部システムへは無作為にリクエストを送るのではなく、連携の必要性を都度チェックし、必要だと判断できる場合にのみ送るようにする。
不必要なリクエストを送らないことで、スループットの低下やリソースの過剰消費を抑える狙い。
必要 or 不要の判断は、前回のリクエスト時のパラメータをログとして保存し、差分チェックを行う。対象フィールドに前回分との差分があれば連携し、なければスキップするという構成。
工夫5. サテライトシステム目線ではPull型でコアシステムに依存する
サテライトシステムで連携に必要なデータを揃える場合は、都度コアシステム側に問い合わせて (参照APIを呼び出して) データを揃える。
コアシステムからサテライトシステムへの連携はPubSubのイベントが起点となるが、以降の処理では参照のキー情報 (IDやユニークキー) のみをCloud Tasksのパラメータで受け渡す。各処理では必要な情報を都度参照して揃え、常に最新のデータ状態で処理が実行される、という前提で処理を組む。
これは、ビジネス特性とシステム構成上、コアとサテライトで明確に主従関係が切られていることが明確であるため、この方針に従うほうがよいと結論づけている。結果として、特に問題は起きていない。
Pull型以外にもPush型などがあるが、どちらを採用するかは先に書いたようにビジネス特性とシステム構成に依るため、絶対解は存在しない。最適解を取れるかどうかの世界。
発見
発見1. システム特性はテクニックと戦略で決まる
システム特性の獲得は抽象度が高く、また現象に現れにくいので難しい。
システム特性の獲得論として、自分の実体験のなかでは2つの要素で決まると考えている。
それは “テクニック” と “戦略” 。
テクニックとは文字通り、リトライ機構の整備やUpsertによるデータ永続の冪等性担保に現れる。テクニックは知っていればすぐに採用できるので即効性がある。
戦略とは、システム構成の選択やクラウドサービスの選択といった、実装よりも手前の「何を使うか」「どう配置するか」といったことを指す。
Pub/Subを使う時点で重複実行を受け入れる代わりに、高可用なシステム連携を実現しやすくなる。
2つの依存関係を疎にできて独立性を担保できるのも、クラウドサービスの選択と連携方式の選択で決まる。
戦略によってシステム特性の獲得容易性 (これまた性質) が規定されるので、システムアーキテクトは戦略にこだわる必要がある。
発見2. 連携で価値を生む系SaaSはコア/サテライト
もし仮に、自分が連携系に強みを持つSaaSを0で立ち上げる場合、全く同じ構成を取ると思う。
コストとの兼ね合いでもあるが、一定飲み込めるなら、マルチテナントで運用されるコアとなるシステムと、シングルテナントで運用されるサテライトを分離して、コアの純度を守りつつ、サテライトで顧客の希望に限界まで応える構成を取る。
結果的にシステムの負債化を防ぎ、顧客要望に応えられることが競合優位性となり、事業のペネトレーション可能性を上げることに繋がる。
今となっては当たり前の感覚だが、一昔前はそういう発想に至れていなかった。
暗黙的に通信のオーバーヘッドを気にしていたところがあるからかもしれない。
非同期処理と結果整合性に対する扱い方を身につけられたことによって、技術の最適解を選択できる幅が広がったところが大きい。
発見3. クラウドサービスをフル活用する時代
クラウドサービスは2019年ごろから使っているが、これまでは真に使いこなせていたとは言い難かった。自分は2026年になってやっと、フルで活用し切れるようになった。クラウドサービス自体は昔から存在してはいたが、うまく使いこなせるほど技術と思考が追いついていなかった。
特に非同期処理系では、今回は話で取り上げなかった大規模データ連携系も含めて、従来よりも遥かに低コストで、なおかつ柔軟性と拡張性を持った上で開発できるようになった。
発見4. AIには代替されにくい領域
AIが開発の大部分を置き換え始めており、プログラマーの職は失われる。
一方で、開発の責任を人が取って推進する領域の仕事は失われないと考えている。
少なくとも10年単位で見たら、10年後も存在しているはず。
AIが開発のスケーラビリティを上げたとしても、今回取り上げたような品質の外部連携をプロンプトだけで実現するのは無理だ。
形としてはできるかもしれないが、運用を考えた場合に、運用容易性や運用安全性までを保証することはできない。なぜなら、AIは運用をしないからだ。
運用は点ではなく線で考える世界で、時間軸も長い。
AIがこれからどれだけ進化しようと、時間軸の長さと、そこにかかるメモリーのコストを払い続けて運用対応し続けられる世界はまだ来ない。
来るかもしれないが、少なくとも10年後に「すべて」を置き換えるのは肌感としてありえないと思っている。難しいと考えている。