ファイル連携 プラクティス
SHARES
導入
なぜファイル連携なのか
なぜファイル連携を選ぶのでしょうか。
それは「状況と制約によっては、最も合理的で最適なデータ連携手段になるから」です。
例として、以下の状況と制約に該当する場合はファイル連携を選択するのが良いと考えます。
- 定時性が求められる (リアルタイム性が求められていない)
- 大規模データをまとめて連携したい (数万レコード超え)
- リカバリーやリトライを容易にしたい (中間データソースの活用)
- 上記を人の手を介さずに持続的に実現したい
ファイル連携は世間ではあまりオープンに取り上げられない連携手段ですが、「確実に今後も活用がされ続けるデータ連携の手段だ」と言いきれます。
適材適所という言葉があるように、データ連携にも状況に応じた最適な手段があり、ファイル連携は優れた連携手段だと考えます。
ファイル連携の知識を体系化する動機
ファイル連携はデータ連携手段の 1 つです。
「データ連携手段」と聞くと、Web API 連携や Webhook といった HTTP を使った選択肢を思い浮かべる方が多いと思います。
これはオープンで小規模なデータを高頻度の同期連携するシーンの方が、機会や知見に遭遇する確率が高く、またオープンであるが故にその知見も広がりやすいからではないかなと推察します。
一方で、今回取り上げるファイル連携は Web API 連携と同じく、データ連携手段の中では王道であるものの、あまりオープンに知見が共有されておらず。また標準規格もないので、考え方や概念は断片的に存在しますが、体系立てて整理されていません。少なくとも日本では。
「なぜなのか?」を考えてみると、ファイル連携を連携手段として選択するシーンがエンタープライズ (= 大規模システム連携) であり、その連携仕様が 2~3 社間で閉じているため、”手段形式の汎用性が低く、オープンに知見共有するインセンティブがないからだ” という仮説を持っています。
仮にそう言われたら一定納得してしまうのですが、これまで複数社のエンタープライズ向けシステム連携を経験した自分の目線では、「本当に転用するナレッジの価値が低いのだろうか?」「本当に体系化できない知識なのだろうか?」という疑問を持ちました。
確かに汎用性が低い点が多く、オープンに知見共有するナレッジ自体が多くないのかもしれません。というより、オープンにできない (しづらい) コミュニティ文化 (開発文化) があったことが大きな要因なのではないかなと思っています。
そういったコミュニティとは一線離れたところ (比較的オープンな方) から育った身として、複数の類似した開発要件に応えた自身の経験を振り返ると、一定の汎用性がある、開発運用の成功に近づくための守るべき要点 (原則のようなもの) が見えてきました。
それらを可能な限り体系化することを目指して、今後類似の開発に取り組む方の助けになれれば良いなと思い、体系化を試みます。
作る側の視点と提示する側の視点
ファイル連携の知識を整理する場合、その知識はファイルを作る側の視点の話なのか?ファイル仕様を提示する側の視点なのか?という 2 つの視点が生まれます。
ここで示す内容は、どちらの視点も含む記述を採用し、特段片方に寄せた書き方はしません。
読んでいただく方の意識を統制できていないため、読み解きに対する負荷を強いることに繋がっていますが、あえて分けないことでファイル連携そのものを理解し、作る側の視点を尊重しながら仕様を提示できる or 提示する側の意図や配慮を汲みながら自由に作れる状態を目指せるようにするためです。
また、読者の対象として開発者以外の”事業開発”や”プロダクトマネージャー”といったプロダクト開発に関わる全ての人に向けて書かれています。
ただし、どの役職に対しても理解しやすい内容にすることは保証していないため、特に事業開発といった開発現場から少し距離のある役職の方にとっては、一部内容が理解できない点があるかもしれません。
その場合は、開発者に声をかけ認識の確認や理解を深める質問などを行い、サポートをもらってください。開発者は 100%理解できる内容に仕上げています。
ファイル連携の全体像
先に全体の関係性を整理した図で示します。概念の存在や関係性をイメージしてください。
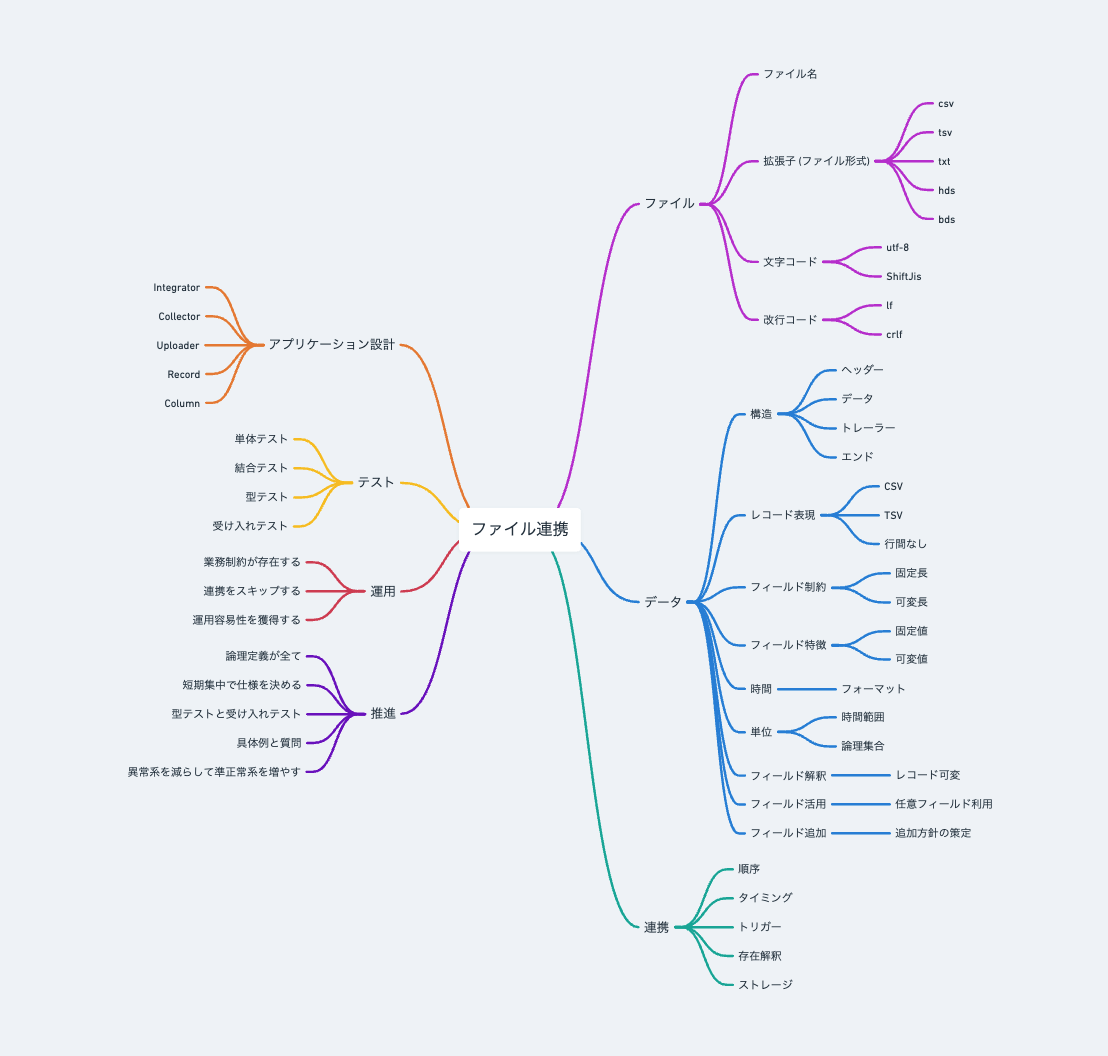
全ての項目を通して理解する必要はありません。関心のある話題のみを選択しても理解できるように書かれています。必要だと感じる箇所のみを参考にしてください。
なお、通しで読むことで体系を理解できるようには書かれており、特に概念の関係性の特徴に注目してみると、なお理解が進むかと思います。
目次
- 導入
- なぜファイル連携なのか
- ファイル連携の知識を体系化する動機
- 作る側の視点と提示する側の視点
- ファイル連携の全体像
- 1. ファイル
- ファイル名
- 拡張子 (ファイル形式)
- 文字コード
- 改行コード
- 2. データ
- ヘッダー, データ, トレーラー, エンド
- CSV,TSV,行間なし
- CSV
- TSV
- 行間なし
- 固定長 / 可変長
- 固定値 / 可変値
- 時間フォーマット (タイムスタンプの扱い)
- ファイルを作る単位, レコードをまとめる単位
- レコードごとにフィールドの意味を変える
- 運用容易性を担保するためのフィールド活用
- 拡張性を担保するためのフィールド追加方針
- 3. 連携
- ファイルを連携するタイミング
- ファイルを連携するトリガー
- ファイルを連携する順序
- ファイルの存在に対する解釈
- ファイルの連携先に選ぶストレージ
- ファイル連携のライフサイクル
- ファイル連携で許可する権限
- 4. アプリケーション設計
- 5. テスト
- 6. 運用
- 業務制約が存在する
- 連携をスキップする
- 運用容易性を獲得する
- 7. 推進
- 論理定義が全て
- 短期集中で仕様を決めにいく
- 異常系を減らして準正常系を増やす
- 型テストと受け入れテストを分ける
- 具体例を挙げてまとめて質問する
- 最後に
- 参考文献
1. ファイル
ファイル名
ファイル名に意味を持たせているケースが多くあります。
鉄板は yyyyMMddhhmmss といった時間表現で、他にもファイルの中身を識別できるようなコード表現 (hogehogeid) を追記していることもあり、地域コードや店舗コード、カテゴリーコードなどがよく見つかります。
もしファイル名に制約がない場合は、自分たちの運用のし易さから逆算して、識別子と日付などを入れたファイル名を選択しましょう。
その時、運用時に “何を気にするのか” から考えて順番を決めると良いです。
コード単位で情報を精査する頻度が多い場合は、 code_yyyyMMdddhhmmss と表現する。
日時で作成するため日単位で精査する場合は、 yyyyMMddhhmmss_code と表現する。
こうすることで、ストレージにある場合の認知のし易さが変わります。
拡張子 (ファイル形式)
拡張子は csv や tsv 、txt が鉄板です。
世間のスタンダードでこれから変わることはほぼないかなと。
他には .json もあるかもしれません。
歴史あるシステムだと、中身は csv や txt の表現で、拡張子は独自の表現になっている場合もあります。
例えば、ヘッダーファイルとボディファイルという 2 つのファイルを別々に分けて扱う場合、それぞれ ヘッダーなら .hds 、ボディなら .bds といった形式があったりします。(※ 手触り感の薄い例かもしれませんが、これは実在する話です)
指定されたら素直に従いましょう。
もし指定がなければ csv や tsvを選びましょう。さらに、ヘッダーファイルとボディファイルの識別はファイル名に特徴を作るのが良いです。 hogehoge_header.csv や hugahuga_body.csv
こうしておくことで、問題発生時の調査が楽になりますし、ファイルの中身を確認する手前で何のファイルのなのかを識別できます。エディタでファイルを開いた時にフォーマッターのサポートを受けられます。
また、拡張子が txt であるが、書き込まれているデータの表現は csv であったり、tsv であったりする場合もあります。初めて遭遇すると「ファイル拡張子と違う!?」と少し驚きますが、”必ずしも表現が保証されている世界ではない” ということも知っておくと良いです。
文字コード
文字コードは utf-8 か shiftjis の 2 択です。他も選択できますが、あまり見かけません。
どちらか選択できるなら無難に世界標準である utf-8 を選びましょう。
改行コード
文字コードに合わせて、改行コードも適切に選ぶ必要があります。
shiftjis の場合は、 crlf を選択しなければいけません。気をつけましょう。
2. データ
ヘッダー, データ, トレーラー, エンド
レコードには位置によってその意味が変わる特徴があります。
位置ごとにレコード名称が決まっており、1 つのフォーマットとして覚えましょう。ちなみにこれは事実上の標準 (デファクトスタンダート) として決まっているだけなので、何かしらの策定があったわけではないです。
例題をあげてみます。
id,title,description,views,createdAt
1,ファイル連携,ファイル連携の攻略,30,2023-05-01 10:00:00
2,Dart入門,Dartの入門,10,2023-06-01 11:00:00
3,Mastering Firestore,マスタリングファイアーストア,20,2023-07-01 11:00:00
xxx,,,60
eee
csv で表現しました。
1 行目の id から始まるところがヘッダー。
2 行目から 4 行目の title から createdAt までに値が入っているのがデータ。
5 行目の xxx から始まり、 60 で終わっているところがトレーラー。
6 行目の eee から始まるところがエンド。
この様に形式の名称が決まっています。
例はあくまで全部盛りの表現で、実際にはヘッダーがなかったり、トレーラーがなかったり、エンドがなかったりと、ケースによって変わります。なので、全てあるのが正ではなく、場合によって存在しないものもあるのが普通だと考えましょう。
ヘッダーは列の意味定義。
データは意味定義に沿ったデータそのもの。
トレーラーはデータのまとまりに区切りをつけるデータで、サンプルではトレーラーの識別子である xxx (これはビルトインで予約語として決まっている識別子だと仮定) と views のフィールドにそれまでの合計の views の数が入っている。
エンドはファイルの終わりを示すもので、サンプルでは eee としています。これ自体がビルトインで予約語として決まっている識別子だと仮定し、これ以降は書き込みデータが存在しない、あっても取り扱わないことを明示的に示します。
ヘッダーとエンドは 1 ファイルで 1 行ずつ入る (場合によってはヘッダーで 2 行入ることもあります) のが一般的ですが、データとトレーラーは複数入ります。
ヘッダー
データ1.1
データ1.2
トレーラー1
データ2.1
データ2.2
データ2.3
トレーラー2
...
エンド
上記の様に、データとのまとまりを占めるトレーラーという存在であるため、複数のトレーラーのまとまりが入る場合もあります。
銀行とのデータ連携での取引履歴データや、EC サイトの注文データなどは、1 ファイルの中に複数のデータと複数のトレーラーが含まれて連携ファイルが構成されているのをよく見かけます。
CSV,TSV,行間なし
カラム間の表現は CSV, TSV, 行間なしの 3 択で、これ以外も考えられますが (| や ” など) 、それらにはほぼ遭遇し得ないと考えて良いです。
もし選べるなら CSV を選びましょう。理由は最も扱いやすく考えることが少ないからです。
TSV だと空文字の扱いを決めたりしなければいけないのと、空文字をnull という予約語にした場合に、視認性が CSV よりも落ちてしまうのが難点です。
行間なしだと視認性がかなり悪いため、絶対に避けたいところですが、場合によっては要求されることもあるので、読み解くことを諦めましょう。また、「行間がない中で内容の識別をどうするのか?」という問いが生まれますが、識別は制約をもって解決します。制約というのは固定長にするというものです。こちらは後に触れます。
CSV
id,title,description,views,createdAt
1,ファイル連携,ファイル連携の攻略,30,2023-05-01 10:00:00
2,Dart入門,Dartの入門,10,2023-06-01 11:00:00
3,Mastering Firestore,マスタリングファイアーストア,20,2023-07-01 11:00:00
xxx,,,60
eee
TSV
id title description views createdAt
1 ファイル連携 ファイル連携の攻略 30 2023-05-0110:00:00
2 Dart入門 Dartの入門 10 2023-06-0111:00:00
3 MasteringFirestore マスタリングファイアーストア 20 2023-07-0111:00:00
xxx 60
eee
行間なし
idtitledescriptionviewscreatedAt
1ファイル連携ファイル連携の攻略302023-05-0110:00:00
2Dart入門Dartの入門102023-06-0111:00:00
3MasteringFirestoreマスタリングファイアーストア202023-07-0111:00:00
xxx60
eee
固定長 / 可変長
フィールドの制約に固定長と可変長があります。
これはフィールドに入力される値の長さが固定か可変なのかという意味です。
(例 : 本の価格表現)
- 固定長 (10 桁が最大で、左辺 0 埋め) :
0000004500 - 可変長 (桁数制限なし) :
4500
可変長は長さに気を使う必要がなく、自由な入力ができます。
固定長は長さに気を使う必要があり、自由な入力ができません。
どちらか選べるなら可変長にしましょう。
固定長が選択されている場合、「長さをどういった表現で保つか」が論点として上がります。
文字列型であれば、左埋めで空文字。整数型であれば、右埋めで 0。などが鉄板の表現です。
これだけで考えることと実装が増えますし、可読性も低下します。
これが固定長のデメリットで、可変長選ぶべき理由の 1 つです。
「固定長は入力内容を厳格に縛れることを意味し、バリデーションとしても機能する」といった言説も見られますが、バリデーションの機能をフォーマットに付随するのはトレードオフとして失うもの (認知負荷の増加, 拡張性の欠如) が大きいのでやめましょう。
データフォーマットに機能性を期待してはいけません。
固定値 / 可変値
フィールドの値は基本的に可変値であることがほとんど (差分そのものに意味があるので当然) ですが、ファイルを多様なシーンで扱っている場合、フィールドの一部が前もって定められた値 (固定値) をセットして利用する or 何も書き込まない (空白) にしておくといったケースがよくあります。
データ仕様をキャッチアップする際にはデータの可変性に注目して、何が固定で何が可変であるかを最初に掴んでおきましょう。ここに注目する理由は、少しでも考えることを減らすためです。
「固定である」という仕様が将来的に変わりうる可能性もあるかもしれませんが、基本は変わらないから「固定」とされているものなので、変わらないという前提を信じて、そもそも考えないようにしましょう。これは見方を変えれば情報の重要性の強弱を何を軸に判断するか?という話です。
可変値がどのように扱われるべきか?という論点だけに集中すればキャッチアップが進みやすくなります。逆にデータ仕様を提示する立場であるならば、最初に前提として固定値は何で可変値は何であるかを示すと開発が進みやすくなるはずです。
時間フォーマット (タイムスタンプの扱い)
時間データにはかなりの確率で遭遇します。遭遇しない方が稀かもしれません。
時間データはフォーマットに気を使いましょう。時間データに関する問題のほとんどはフォーマットの扱いが不透明であることに起因します。
ここでのフォーマットの扱いというのは、データがある場合にどこまでの値を表示するのか、またそれは何の形式なのか、ない場合にはどう扱うのかというものです。
例えば 2023/04/23 20:30:40 というデータがある場合、 2023-04-23 という表現にするのか 2023/04/23 という表現にするのか。あるいは時間だけが欲しいケースで 20:30 という表現を選択肢、秒表現は捨てるのかなど。そして、もしデータがない場合は 2023/04/23 23:59:59という当日最終時刻で扱うといったイレギュラーケースの考慮なども考えられます。
「実はこっちの表現が良かったです」といった仕様変更が頻繁に起こりやすい箇所であるため、「フォーマットをどうするか」は外せない論点です。必ず確認しましょう。
ファイルを作る単位, レコードをまとめる単位
ファイル連携で扱うデータは、時間範囲と論理集合の 2 軸で決まります。
日次連携であれば日付単位のデータ、月次連携であれば月単位のデータなど。どの範囲のデータを取り扱いたいのかで時間範囲を決めます。制約がない場合は考えません。
論理集合は店舗単位やカテゴリー単位、地域単位など、ドメインで扱う特徴差分によるものを指します。EC の売上データであれば店舗単位で区切ることが、データを利用する側としても嬉しです。これが仮に注文主郵便番号の基準で扱われていたら、データ連結などが後に必要になって不便です。
「どの単位で区切ると業務上扱いやすいのか?」という問いから逆算すると、自然と基準が見えてくると思います。
ファイルを作る側の視点で仕様を理解する場合は、必ずどの単位で扱って欲しい (扱うべき) なのかを確認しましょう。ここが誤っていると実装の出戻りが大きくなりますし、運用を支えるリカバリーツールの考慮にも影響を及ぼします。
レコードごとにフィールドの意味を変える
ファイル連携のデメリットとして一番に挙げられるのが「表現制約」です。
レコード単位でしかデータを表せないため、グループで意味を持たせたい場合や、ケースによって書き込む値を変えたい場合には連携手段自体の選択に渋る場面があるかもしれません。
1 つの解決策としてあるのが、レコードごとにフィールドに書き込む値を変えることです。
例として以下の構成でデータレコードが存在するケースを考えます。
- 注文レコード
- 購入商品レコード
- 手数料レコード
- 値引きレコード
- ポイント付与レコード
レコード定義は以下で考える。
orderId,name,type,price,point
この場合に以下のような表現になる。
orderId,name,type,price,point
111222333,明細,1,2000,100
111222333,トマト,2,300,0
111222333,肉、2,500,0
111222333,カレー粉,2,200,0
111222333,手数料,3,200,0
111222333,値引き,4,100,0
111222333,ポイント付与,5,0,200
このデータレコード群で注目すべきは type というフィールド。これがデータレコードの種別性を追加しており、type によって price と point に書き込む意味と制約を追加しています。
type が 1 の場合は type が 2 と 3 の値の合計値から type4 の値を引いた最終請求金額が price フィールドに定義。
type2 と 3 は単体としての金額が記述され、type4 には値引き額が記述される。type5 には price フィールドは 0 で point フィールドに付与予定のポイント数が記述されます。
このようにフィールドにタイプと定義し、フィールドの意味をタイプ定義によって解釈を変えるというテクニックがファイル連携で使われていたりします。ものすごく短略化した例なので、「逆に複雑になるから選択するべきではない」というコメントもきそうですが、選択可能なテクニックとして紹介しました。実際に使われているシーンは結構な頻度で遭遇するので、知っていて損はないと思います。
実際に使うかどうかは前提条件や将来の運用容易性を考慮した上で考えたほうが良い。場合によってはうまく使えるし、場合によっては悪さも働く。データ連携ではそれなりに重宝されるテクニックです。
運用容易性を担保するためのフィールド活用
ファイルの中身は全てが必須になっている場合よりも、一部は任意 (固定値) になっている場合があります。また、書き込まれるデータは自分たちが取り扱いたいデータではなく、取り込む側が扱いたいデータになるので、障害発生時などに参照したいデータが必ずしもファイルに書き込まれているとは限りません。
そういった場合に運用容易性 (障害発生時の検知をしやすくすること) を担保するためにオススメするテクニックに、任意フィールドの活用があります。
これは、取り込む側が求めていないデータ記述であったとしても、書き込む側目線で運用を楽にするために必要なデータを意図的に書き込んで利用することです。
例えば、カラム B は任意フィールドで固定値の数字 10 桁が入れられる要件だったとします。
対して書き込む側はデータの ID を本来は書き込む必要がないが、運用上確認しやすくするために書き込んでおきたい、さらにそのデータは 8 桁の数字表現であったとします。
その場合、カラム B の 10 桁フィールドに対してデータ ID を左辺 0 埋めの表現で 10 桁に変換し書き込んでおきます。こうしておくことで何らか連携でエラーが発生し問題の所在を突き止めるための調査材料として ID を活用できるようにし、問題調査を楽にします。
カラム B の固定値 : 0000000000
書き込みたい ID : 19283648
カラム B に書き込む ID 0019283648
泥臭いテクニックですが、こういった小さな工夫が運用負荷を落とすことに繋がります。
拡張性を担保するためのフィールド追加方針
ファイル連携を選択した後に悩みとなるのが、将来に来るであろう拡張要求に対する対応です。
事業やプロダクトが成長するにつれてデータ連携した要求が増えていきます。
ファイル連携が 1:1 の関係でのみ利用されるなら、両者の合意をとってフィールドの追加変更対応をすれば問題ありません。しかし、大抵の場合は 1:N の関係でファイル連携機構を利用していることが多く、1 が N の要求に応えなければいけない状況のほうが多いです。
この場合、1 が N1 の要求に応えてファイルフォーマットにフィールド定義を追加した場合、N2 が想定していないフィールドが入ったことによって取り込みエラーになるケースが起き得ます。
このフィールド追加によるコンフリクトは事前にどういう対応をしていくのかを、ファイルフォーマットを提示する側と取り込み側の双方で合意をとっておくことで回避しましょう。
主導権を握れるのであれば、データ提供側がフィールドを将来的に自由に追加していき、尚且つ使用していないフィールドには初期値が入ることを決めておくのが良いでしょう。
データファイルの取り込み側はフィールドが可変で追加されることをあらかじめ想定した取り込みの作りにしておき、取り込み側目線で不要だと判断するフィールド定義は初めから参照利用しないようにしておきます。
この合意が取れておくと、仮にフィールドが追加されたとしても取り込み側は何も影響を受けなくなり、フィールドを追加する側は N をケアすることなくフィールドを追加できます。
ただし、扱いやすいからといって提供側が N 数分の固有フィールドを追加しすぎると神ファイルが生まれてアプリケーション側に複雑な処理がよってしまうため、なるべく N に総合的に効くであろうフィールドのみを追加するようにケアしましょう。
3. 連携
ファイルを連携するタイミング
連携タイミングは必ず決める論点です。
いつまでに連携してほしいのか、その期限はデータ参照の観点で妥当なのかを確認しましょう。
タイミングはファイルを取り込む側のシステム的な制約が現れるため、後続処理にどういったことをやりたいのかまでヒアリングしておくことをお勧めします。そうすることで、何らか連携に失敗した場合のファイル連携のリカバリーをどうするのか?という論点に広げることができ、連携としての信頼性獲得に向けた対策の議論に進めやすくなります。
ファイルを連携するトリガー
連携のトリガーは 3 択です。定時実行 or アクション or データ
定時実行は深夜 1 時に連携処理を始めるといったもので、単純に CronTab などで制御しましょう。
アクションは提示実行よりも考えることが増えます。
「アクション」というのは、特定の業務作業が終了し、連携実施の事前条件が満たされた状態で人の行動を起因に処理が始まるものです。
例えば物流の出荷情報の連携は、事前に出荷準備が完了している必要があり、出荷準備完了の状態を物理とシステムの両方で認識し、連携を始める必要があります。これが仮に物理は完了できていないのにシステムで先に連携してしまった場合、後続で続く配達業務に支障が生まれる可能性があります。システムは連携完了しているが物理は完了していないので実際は配達を始められない (!) といった問題状況です。
このように、「事前条件を満たしているか?」というバリデーション処理に対する考慮が、アクション起因では必要になる確率が高いため、開発の難易度が上がります。
ファイルを連携する順序
ファイル連携に順序制約がある場合は、実現に捻りが必要で開発難易度がグッと上がります。
例えば、同一のデータソースを参照して類似性の高いファイル A とファイル B を作成します。連携には順序制約があり、ファイル A をストレージ A に N 時までに連携していた場合にのみ、ファイル B をストレージ B に T 時まで連携する。といったケースです。
連携状態の管理が必要になる場合は、その状態管理 (連携の可否) を連携する側が判断しなければいけないため大変です。時間制約の側面 (いつまでに連携する) もあり、気を使うことが多いです。
なるべく連携で状態を扱う仕様は避けましょう。
運用が非常に大変で(リカバリーの大変さ や整合性チェックの大変さ)、開発者への負担が大きいです。連携で状態管理するのではなく、取り込み時のバリデーション or データ加工で整合性を取り直す構造にするのをオススメします。
もし順序制約が存在するファイル連携でファイルを提示する側になった場合は、永続データを活用した連携処理を組むことになると思います。ファイル連携で状態管理するのはあまり考えたくないものですが、そういうものだと受け入れてなるべく素朴な作りで状態管理を介したファイル連携ができるようにしましょう。
ファイルの存在に対する解釈
ファイルの存在に対する解釈を揃えましょう。
理想は、連携内容のある/なしに関わらずファイルは必ず作成し、取り込み側がファイルの取り込みで判断するです。
例えば、定時実行でファイル連携をし前日分のデータが連携対象である場合に、連携対象データがなかったとします。その場合ファイルを作る/作らないの判断をどうするのか?という問いに至ります。この場合はファイルを作ることにします。
データのあるなしでファイルの有無に差分を作るのではなく、ファイルの中身の容量のあるなしで判断した方が、連携する側の処理が単純になるのと、ファイルの存在に対して一貫性が持てるようになり、ファイルの存在を確認するだけで処理の実施可否を判断できるようになるからです。
ファイルの連携先に選ぶストレージ
連携先のストレージは運用容易性を最重要に選びましょう。
モダンな開発技術を使えるのであれば、クラウドサービスのファイルストレージサービス一択です。クレデンシャルを共有してファイル参照できる状態を作りましょう。
この際 1(ファイル提供側):N(ファイル取り込み側)という関係値が作られる可能性があります。その際にストレージに対するオーナーシップはファイル提供側にします。そうすることでリカバリーやエラーが発生した際の復旧が容易になるからです。ファイル取り込み側は提供された環境でファイルを参照し、取り込むことだけに徹すほうが責任分解点が明確で、わかりやすくなります。
クラウドストレージを選択できないケースとして FTP サーバーへのアップロードがありえます。開発運用上は苦しい選択ですが飲み込みましょう。
ファイル連携のライフサイクル
ファイル連携のライフサイクルを整理しましょう。
ライフサイクルとはその名の通り、ファイルが作られてから削除されるまでの流れのことです。
ファイルを作ることに注目が集まりますが、終わりも決めなければいけません。いつ、何を条件に削除するのかを決めておき、ストレージの容量を圧迫しないようにケアしましょう。
ファイルの用途や鮮度にもよりますが、おおよそ 10 日から 30 日ほどストレージに置いていくのが良いです。長いと 30 日 (主に月単位での検査が走るケースがあるので) ほど置いておく場合もあります。
ファイル連携で許可する権限
ストレージに置いたファイルに対する操作にも共通認識を取りましょう。
ファイルは提供側が定めたライフサイクルから外れた操作は基本は受け付けない設計にします。
ファイルの参照側がファイルの取り込みの判断基準としてストレージに存在するファイルを Delete したいといった要望を上げる場合があります。要望に応えることもできますが、運用容易性の観点からは削除をするべきではありません。ストレージに起き続けるファイルはバックアップ用でもありますし、ファイル生成の責任対する証明にもなります。
連携で許可する権限は参照側は参照のみにすることを推奨します。
4. アプリケーション設計
セクションを一応設けたものの、特筆して述べる内容はありませんでした。
普段は以下のクラス定義を用いて連携処理を実装しています。
Record, Column, Uploader, Builder, Integrator, DataCollector
実装定義に困っている方は 「オブジェクト設計スタイルガイド」を参考にしてみると良いかもしれません。ファイル連携に関係なく全てのオブジェクトデザインに置いて有用な指針が示されています。
5. テスト
このセクションを書き切る前に、別の記事でテストに対する方針を記載したものがあるので、そちらの内容を参照してください。
POS 連携について書かれた記事ではありますが、テストのセクションは POS に関係なく使える内容になっています。
「Stailer と POS 連携」”段階的なテスト実施 (開発テスト / 型テスト / 受け入れテスト)”
6. 運用
業務制約が存在する
ファイル連携をデザインする上で、連携の前後に業務制約がないか確認しましょう。
例えば、連携を業務の操作によって開始し、連携完了をトリガーに次の業務に移る必要性がある場合、連携がいつ始まっていつ終わるのか、完了までに許容できる時間、連携が何らかの理由で失敗した場合の代替手段など、業務と密接に関係する場合は考えることが大きく増えます。
この考慮ポイントは全て仕様に反映されることになり、デザインが複雑になる可能性があります。実行開始から 3 分以内に数万件のデータを連携したい場合は非同期処理や並列化といったアプローチが選択されます。
連携の前後に存在する業務制約がないのかを考えると、より良い連携デザインが組めます。
連携をスキップする
ファイル連携を実施しないケース考えましょう。
「年末年始の休業時に連携を必要としない場合はどうなるのか?」が一番の好例です。
空記述のファイルをストレージにおくのか、そもそもファイルをつくらないのかなどが選択肢と考えられます。また、年末年始といった特殊な期間に限らず、毎週木曜日は休業するといったケースもあり得ます。
どういう場合で連携を避けるのか、避ける場合のアプローチを検討すると良い連携デザインが組めます。
運用容易性を獲得する
ファイル連携は連携手段としての特徴上、大規模データになるケースが多いです。大規模であるほど障害時の対応が困難になりやすく、運用容易性獲得のインパクトが大きくなります。
運用が楽であることは非常に重要です。リトライ, リカバリー, ロールバック, バックアップといった運用容易性を獲得するために推奨されるアプローチは惜しみなく採用しましょう。
7. 推進
論理定義が全て
ファイル連携は論理定義が全てです。
とりあえず作って出し、不確実な中で探索しながら〜といった SoE の側面は全くありません。
SoR としての正しさが求められます。
これは考えを変えれば、「論理定義がまともにできれば楽に開発ができる」「エンゲージメントに寄与する開発よりも確実に 100 点を取れる開発ができる」と捉えることもできます。
正常系, 準正常系, 異常系それぞれの仕様を漏れなく押さえて論理定義し切ることを目指しましょう。
論理定義の質で成果の質が決まるので、緻密な定義ができていれば後の開発運用は楽になります。
逆に開発運用の負荷が高い場合は、論理定義の質が悪かったと捉えて良いでしょう。
論理定義でどこに注意すべきかはこれまで挙げてきた要点が全てです。
短期集中で仕様を決めにいく
ファイル連携の仕様調整や確認は短期集中でやり切った方が良いです。
1 ヶ月かけるのは時間をかけ過ぎており、1 週間 (5 営業日) 以内に終わらせるのが理想です。
ただし、仕様自体の確認調査の時間が必要になる場合もあるので 2 週間 (10 営業日) ほど必要になるのが一般的です。2 週間は合格点だと考えましょう。
短期集中した方が良いのは、その方が時間効率が良いからです。SoR 的なシステムの仕様定義は長い時間をかけて解決する問題ではありません。少なくともファイル連携は。
長く論点を浮かせておくのは思考リソース的には不健全なので、仮決めでもいいから仕様を決めてしまい、後で都合が悪くなったタイミングで修正する、修正することを織り込んで (修正余地を設けて) 仕様を定義していくのが良いです。
異常系を減らして準正常系を増やす
これまでの経験を振り返ると、ファイル連携では異常系で捌くことを減らして準正常系で捌くことを意識的に増やしたほうが運用容易性が上がるように思いました。
例えば連携するデータの一部が連携元に存在しなかった場合、連携ファイルを作らないのではなく、連携ファイルを初期値をセットして作り、後でリカバリーするといったケースです。
リカバリーの仕方にもファイルを作り直したり、部分だけ書き換えたりする手段があります。
異常系とみなしてそもそもファイルを作らないことも 1 つの正解ですが、異常系だったとしても先にファイルだけを作ってしまい、あとからデータが不足していた一部分だけを手動などで書き換えたりしたほうが、実は運用上では楽だったりします。
厳密な運用を強いる場合は正常系と異常系を分け切って、準正常系の余地を残さない形を取りますが、ファイル連携においては運用容易性を担保するために準正常系捌ける余地を残し、それをうまく活用するのが良いと思います。
型テストと受け入れテストを分ける
型テストと受け入れテストは別で行いましょう。
型テストが通っていれば、開発側はその型の範囲から外れないファイルを作るように内部実装を作り込めば良いだけになるので、気が楽です。
おおよそ後過程のテストも通ることが保証されますが、受け入れテストで型テストで確認できなかった点が見つかるかもしれません。受け入れテストもやりましょう。
具体例を挙げてまとめて質問する
これはシステム連携に関わる開発推進全般に言えることでもありますが、連携に関わる仕様や要件を握る場合には、なるべく具体例を挙げて質問しましょう。
全く異なる文脈と異なる視点を持つ相手と、共通の連携仕様を合意する過程は非常に難易度が高いです。「仕様書に沿って開発をすれば良い」と言うのは簡単ですが、仕様書が読み手の想定を欠いた内容であることや、仕様書でカバーできていない暗黙仕様の存在ががファイル連携ではよくあります。そういった難しい状況を突破するための 1 つのテクニックは、具体で会話することです。
特に具体例を挙げるのがよく、「ケーススタディとして A ということが考えられた場合の想定挙動は何ですか? AAA という振る舞いに変わると考えていますが合っていますか?」と問いと推論によって導き出した具体例、そして現在の前提を交えて会話しましょう。
最後に
これまでファイル連携の開発に取り組んできた中で培った知識を整理し、「なぜ、ファイル連携を選択するのか?」という問いから始まり、「ファイル」「データ」「連携」「アプリケーション設計」「テスト」「運用」「推進」とより良いファイル連携を実現する上で押さえておくべきプラクティスを網羅的に触れてきました。
全てプラクティスは採用する必要はなく、部分的に迷いや合理性の判断がつきづらい箇所で採用してもらえれば良いと思います。絶対的な正解は存在しませんが、高確率で成功に近づける解を具体的な例と明確な根拠を持って示したつもりです。
ソフトウェア業界が発展し続けていく以上、これまで以上にデータ連携を実施するシーンは増えていくと思います。連携手段が検討される中で、ファイル連携が有用な連携手段であると判断できる際には迷わず連携手段として採用されてほしいと思っています。
その際に、ここで記載された内容がどんな形であれ、実装者の方の前向きな技術的意思決定を手助けするようなものとなれれば、この上なく嬉しい限りです。より良い連携開発ができることを願います。
参考文献
この記事に合わせて以下の文献にも触れるとより解像度が上がるので、追加で参照してみてください。